データベース設計では、「どの情報をどのテーブルに置くか」が重要です。正規化は、データの重複や不整合を減らすための考え方です。
一言でいうと
正規化は、同じ情報を何度も持たないようにテーブルを分け、データの更新漏れを防ぐ考え方です。
悪い例
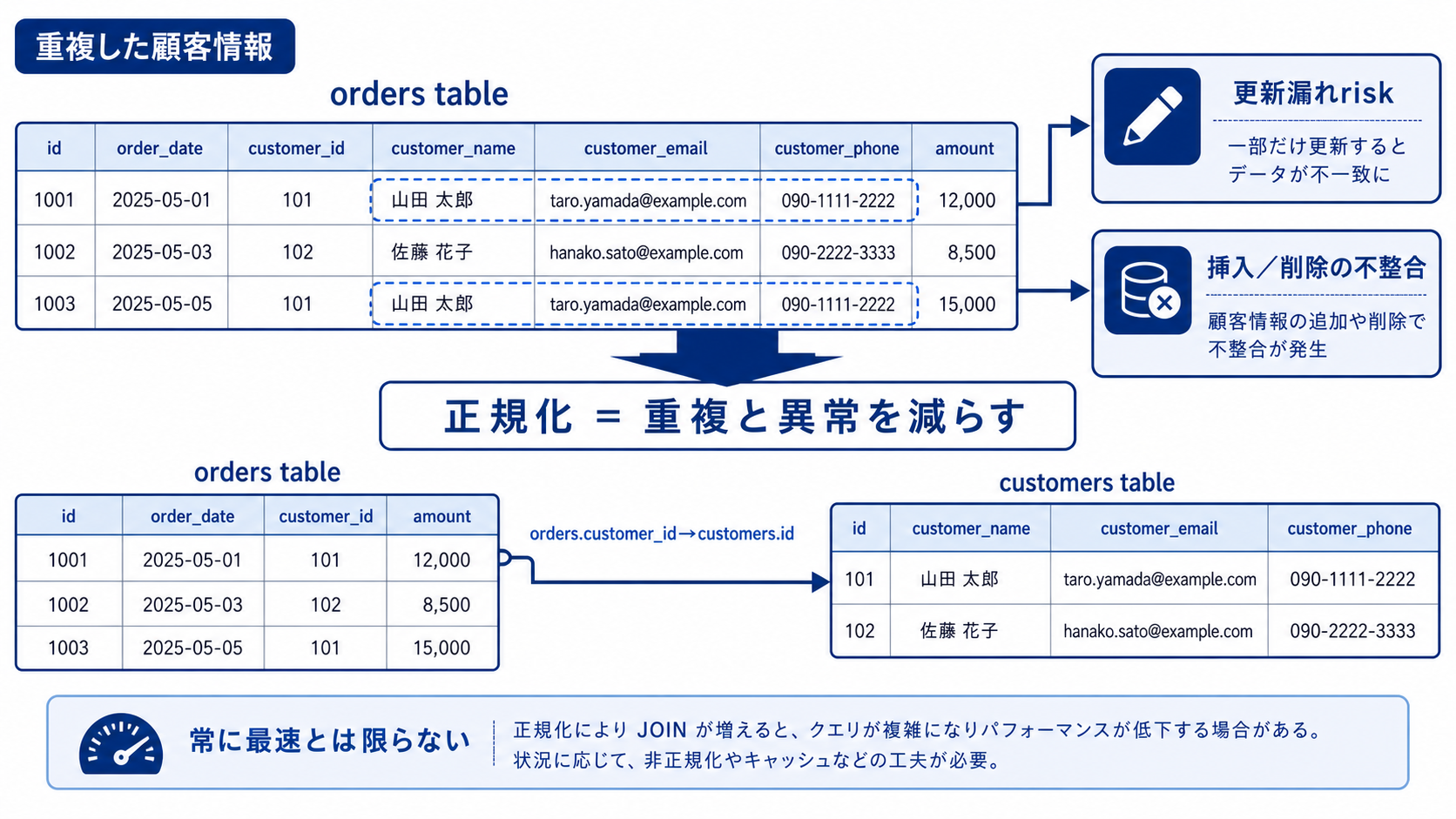
注文データを次のように1つのテーブルにまとめたとします。
| order_id | user_name | user_email | product_name | price |
|---|---|---|---|---|
| 1 | Sato | sato@example.com | Keyboard | 12000 |
| 2 | Sato | sato@example.com | Mouse | 3000 |
| 3 | Suzuki | suzuki@example.com | Monitor | 25000 |
この形はわかりやすいですが、問題があります。
- 同じユーザー情報が何度も出る
- メールアドレス変更時に複数行を直す必要がある
- 直し忘れると同じユーザーなのに違う情報になる
テーブルを分ける
ユーザー、注文、商品を分けると、重複を減らせます。
CREATE TABLE users (
id INTEGER PRIMARY KEY,
name TEXT NOT NULL,
email TEXT NOT NULL UNIQUE
);
CREATE TABLE products (
id INTEGER PRIMARY KEY,
name TEXT NOT NULL,
price INTEGER NOT NULL
);
CREATE TABLE orders (
id INTEGER PRIMARY KEY,
user_id INTEGER NOT NULL REFERENCES users(id),
product_id INTEGER NOT NULL REFERENCES products(id)
);
この形では、ユーザーのメールアドレスは users に1回だけ保存します。
正規化で防げる問題
| 問題 | 内容 |
|---|---|
| 重複 | 同じ情報を複数行に持つ |
| 更新漏れ | 片方だけ直して別の行が古いままになる |
| 削除異常 | ある行を消すと必要な情報まで消える |
| 挿入異常 | 注文がないと商品やユーザーを登録できない |
正規化の目的は、きれいな理論を守ることではなく、データが壊れにくい形にすることです。
分けすぎにも注意
正規化は重要ですが、何でも細かく分ければよいわけではありません。
たとえば、ユーザーの表示名を姓と名に分けるかは、サービスの要件によります。
| 設計 | 向いている場合 |
|---|---|
name だけ | 表示名として使えればよい |
first_name / last_name | 姓名を別々に扱う必要がある |
必要な使い方がないのに細かく分けすぎると、SQLや画面実装が複雑になります。
非正規化とは
あえて重複を持つ設計をすることもあります。これを非正規化と呼ぶことがあります。
たとえば、注文時点の商品名や価格を order_items に保存するケースです。
CREATE TABLE order_items (
id INTEGER PRIMARY KEY,
order_id INTEGER NOT NULL,
product_id INTEGER NOT NULL,
product_name TEXT NOT NULL,
unit_price INTEGER NOT NULL
);
商品マスタの価格が後で変わっても、過去の注文金額は変わってはいけません。このような場合は、注文時点の情報をあえて持ちます。
よくある誤解
| 誤解 | 実際 |
|---|---|
| 正規化すれば常に正しい | 要件によって非正規化も必要です |
| テーブルは少ないほどよい | 重複や更新漏れが増えることがあります |
| テーブルは多いほどよい | JOINや実装が複雑になります |
| 価格は商品テーブルだけに置けばよい | 注文時点の価格を保存すべき場面があります |
まとめ
正規化は、同じ情報を何度も保存せず、データの不整合を減らすための考え方です。ただし、履歴や表示速度などの理由であえて重複を持つこともあります。大切なのは、どの情報が変わるのか、どの時点の情報を残すのかを考えることです。
参考リソース
← 一覧に戻るPR
PR