データが少ないうちは、どんなSQLでもすぐに結果が返ります。しかし、行数が増えると検索が遅くなることがあります。そのときに重要になるのがインデックスです。
一言でいうと
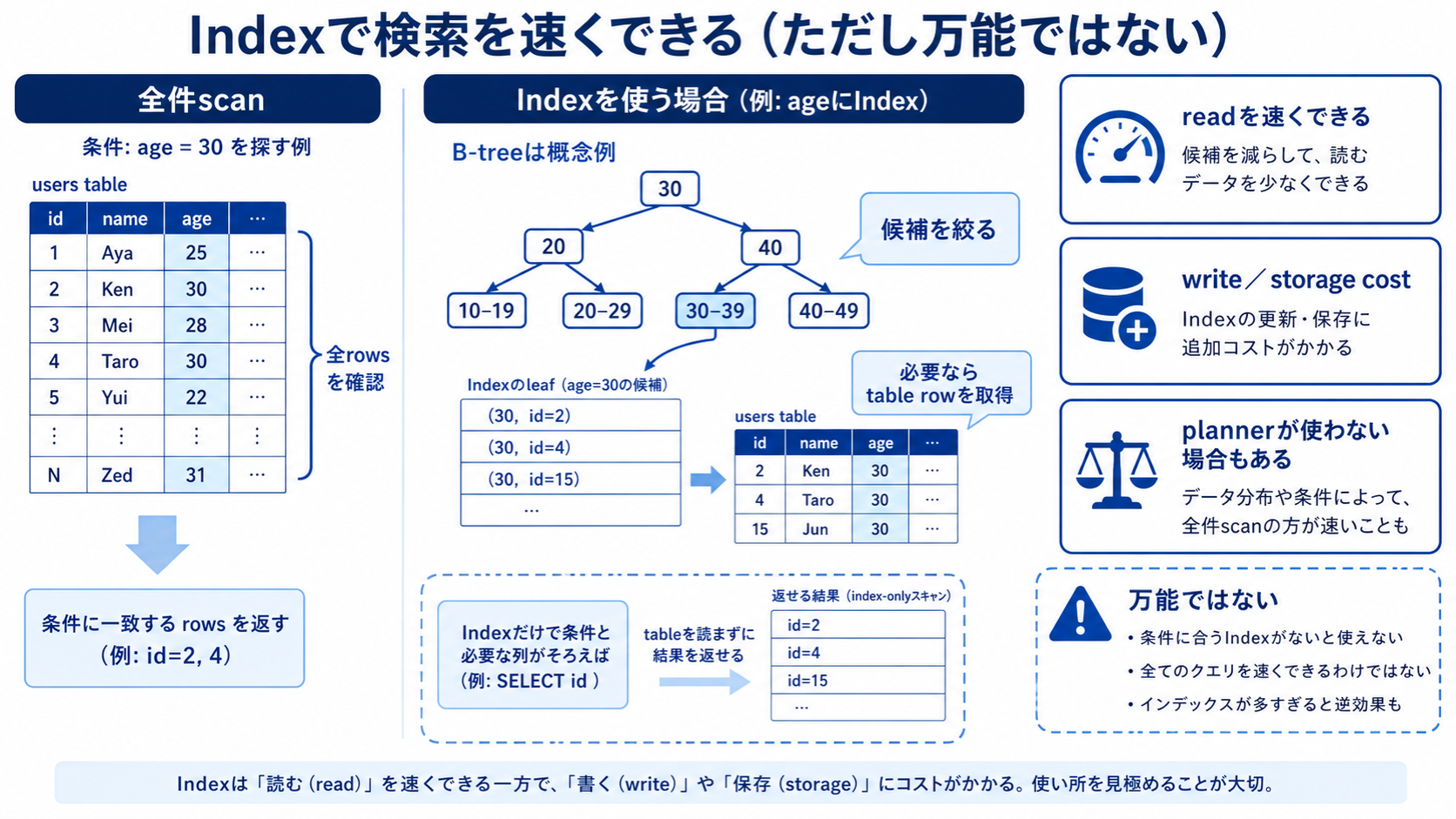
インデックスは、テーブル全体を毎回探さずに目的の行へ近づくための索引です。
全件スキャンとは
たとえば、users テーブルに100万行あるとします。
SELECT *
FROM users
WHERE email = 'sato@example.com';
インデックスがなければ、データベースは多くの場合、上から順番に email を確認します。これを全件スキャンと呼びます。
行数が少なければ問題になりませんが、行数が増えると時間がかかります。
インデックスのイメージ
本の索引を考えるとわかりやすいです。ある用語を探すとき、本を1ページ目から読むより、索引でページ番号を見た方が早いです。
データベースのインデックスも、特定の列の値から該当行を探しやすくするための構造です。
CREATE INDEX idx_users_email
ON users (email);
このインデックスがあると、email を条件にした検索が速くなる可能性があります。
インデックスが効きやすい場面
| 場面 | 例 |
|---|---|
WHERE でよく使う列 | WHERE email = ... |
| JOINで使う列 | orders.user_id |
| 並び替えで使う列 | ORDER BY created_at |
| 一意性を守る列 | email UNIQUE |
インデックスは、よく検索条件やJOIN条件に使う列に貼る候補になります。
インデックスを貼れば常に速いわけではない
インデックスにはコストもあります。
| コスト | 内容 |
|---|---|
| 書き込みが遅くなる | INSERTやUPDATE時にインデックスも更新する |
| 容量を使う | インデックス用のデータ構造が必要 |
| 選ばれない場合がある | データ件数や条件によって使われない |
たとえば、ほとんどの行が active = true の列にインデックスを貼っても、効果が小さい場合があります。
複合インデックス
複数列を組み合わせたインデックスもあります。
CREATE INDEX idx_orders_user_status
ON orders (user_id, status);
これは、user_id と status を組み合わせてよく検索する場合に候補になります。
ただし、複合インデックスは列の順番が重要です。深く扱う前に、まず単一列インデックスと実行計画を確認する習慣を持つとよいです。
EXPLAINで確認する
インデックスが使われているかは、EXPLAIN で確認します。
EXPLAIN
SELECT *
FROM users
WHERE email = 'sato@example.com';
結果に Index Scan のような表示があれば、インデックスが使われている可能性があります。Seq Scan は全件スキャンを意味します。
インデックスは作って終わりではなく、EXPLAINで使われ方を確認します。
よくある誤解
| 誤解 | 実際 |
|---|---|
| インデックスは多いほど速い | 書き込みや容量のコストがあります |
| すべてのWHEREに効く | 条件や関数の使い方で効かない場合があります |
| 小さいテーブルにも必須 | 行数が少ないと不要なことがあります |
| 作れば必ず使われる | オプティマイザが使わない判断をすることがあります |
まとめ
インデックスは、テーブル全体を毎回探さず、目的の行へ近づくための索引です。WHERE、JOIN、ORDER BY でよく使う列が候補になります。ただし、貼りすぎると書き込みや容量のコストが増えるため、EXPLAIN で確認しながら使います。