Unicodeとは、世界中の文字に番号を割り当てるための標準です。日本語、英数字、記号、絵文字などを同じルールで扱うための土台になります。
一言でいうと
Unicodeは「文字に番号を付ける標準」であり、UTF-8やUTF-16はその番号を実際のデータとして保存・通信する方式です。
用語の整理
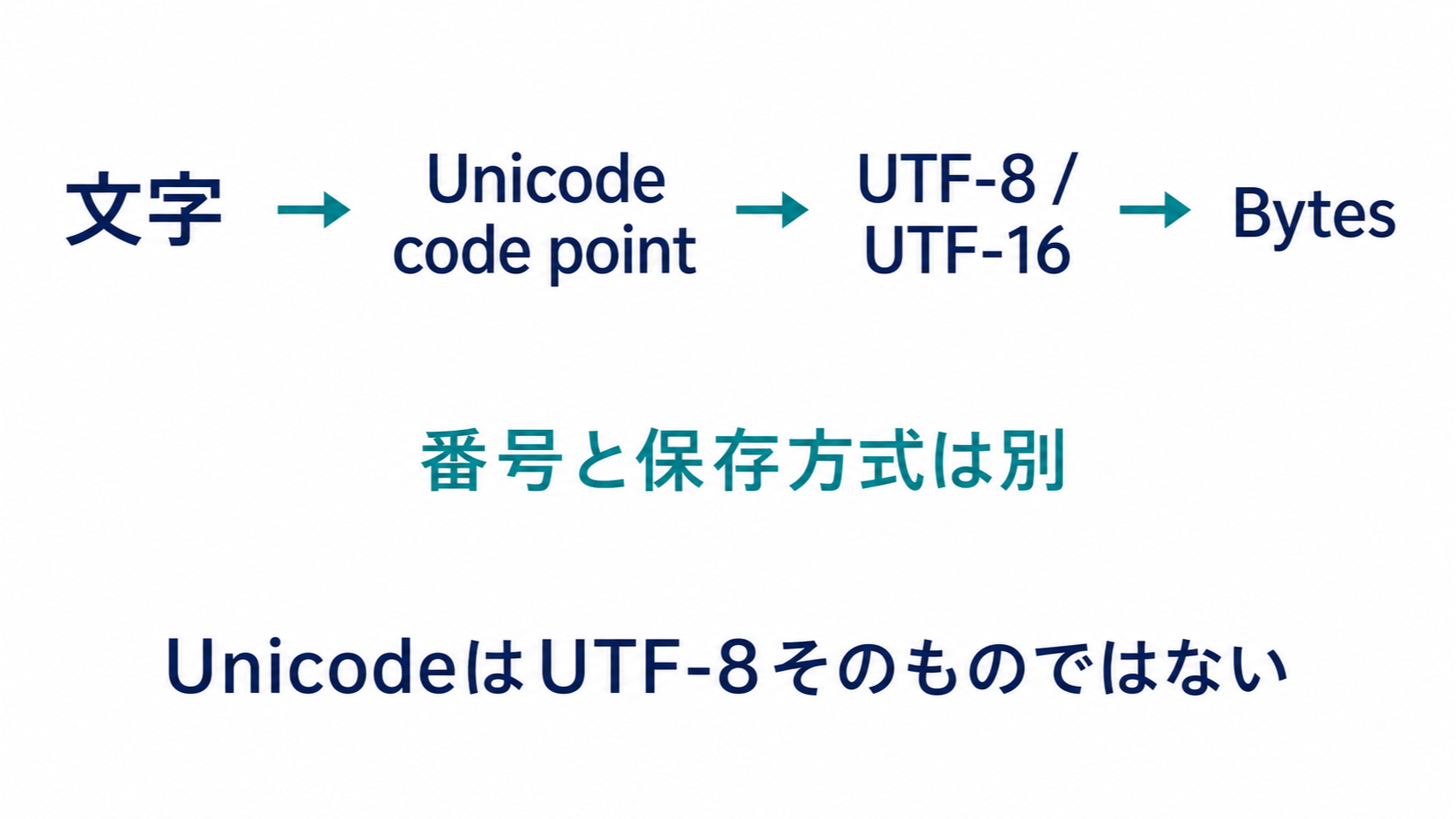
| 用語 | 意味 |
|---|---|
| 文字 | A、あ、😀 のように人間が読むもの |
| コードポイント | Unicodeで割り当てられた番号 |
| エンコーディング | コードポイントをバイト列に変換する方式 |
| UTF-8 | Webでよく使われるエンコーディング |
| UTF-16 | JavaScript文字列の内部表現で重要な方式 |
たとえば、A は Unicode では U+0041 です。あ は U+3042 です。
コードポイントとは
コードポイントは、Unicode上の文字番号です。
| 文字 | コードポイント |
|---|---|
A | U+0041 |
0 | U+0030 |
あ | U+3042 |
ア | U+30A2 |
ア | U+FF71 |
同じ「ア」に見える文字でも、全角カタカナの ア と半角カタカナの ア は別のコードポイントです。
文字コードという言葉の注意
日本語では「文字コード」という言葉が広く使われますが、会話の中で複数の意味を持つことがあります。
| 言い方 | 指している可能性 |
|---|---|
| 文字コード | Unicodeの番号 |
| 文字コード | UTF-8やShift_JISのような符号化方式 |
| 文字コード | ファイルの保存形式 |
| 文字コード | charCodeAt() の戻り値 |
混乱を避けるには、「コードポイント」「UTF-8」「UTF-16」「バイト列」のように分けて言うと安全です。
UnicodeとJavaScript
JavaScriptでは、文字列はUnicode文字列として扱われます。ただし、charCodeAt() はUnicodeコードポイントではなく、UTF-16コード単位を返します。
console.log("A".charCodeAt(0).toString(16)); // 41
console.log("あ".charCodeAt(0).toString(16)); // 3042
英数字や多くの日本語では直感通りに見えますが、絵文字などでは注意が必要です。
Unicodeが必要な理由
昔は、言語や地域ごとに異なる文字コードが使われていました。そのため、同じバイト列でも環境によって別の文字に見えることがありました。
Unicodeは、世界中の文字を共通の番号体系で扱うことで、文字化けや互換性の問題を減らします。
現代のWebでは、特別な理由がない限りUTF-8を使うのが基本です。
よくある誤解
| 誤解 | 実際 |
|---|---|
| UnicodeとUTF-8は同じ | Unicodeは文字番号の標準、UTF-8は符号化方式です |
| 1文字は必ず1バイト | 日本語や絵文字は複数バイトになります |
| 見た目が同じなら同じ文字 | コードポイントが違う場合があります |
JavaScriptの charCodeAt() は常にコードポイントを返す | UTF-16コード単位を返します |
まとめ
Unicodeは文字に番号を付ける標準で、UTF-8やUTF-16はその番号を保存・通信するための方式です。JavaScriptの文字列処理では、コードポイント、UTF-16コード単位、見た目の文字を分けて考えることが重要です。
参考リソース
← 一覧に戻るPR
PR