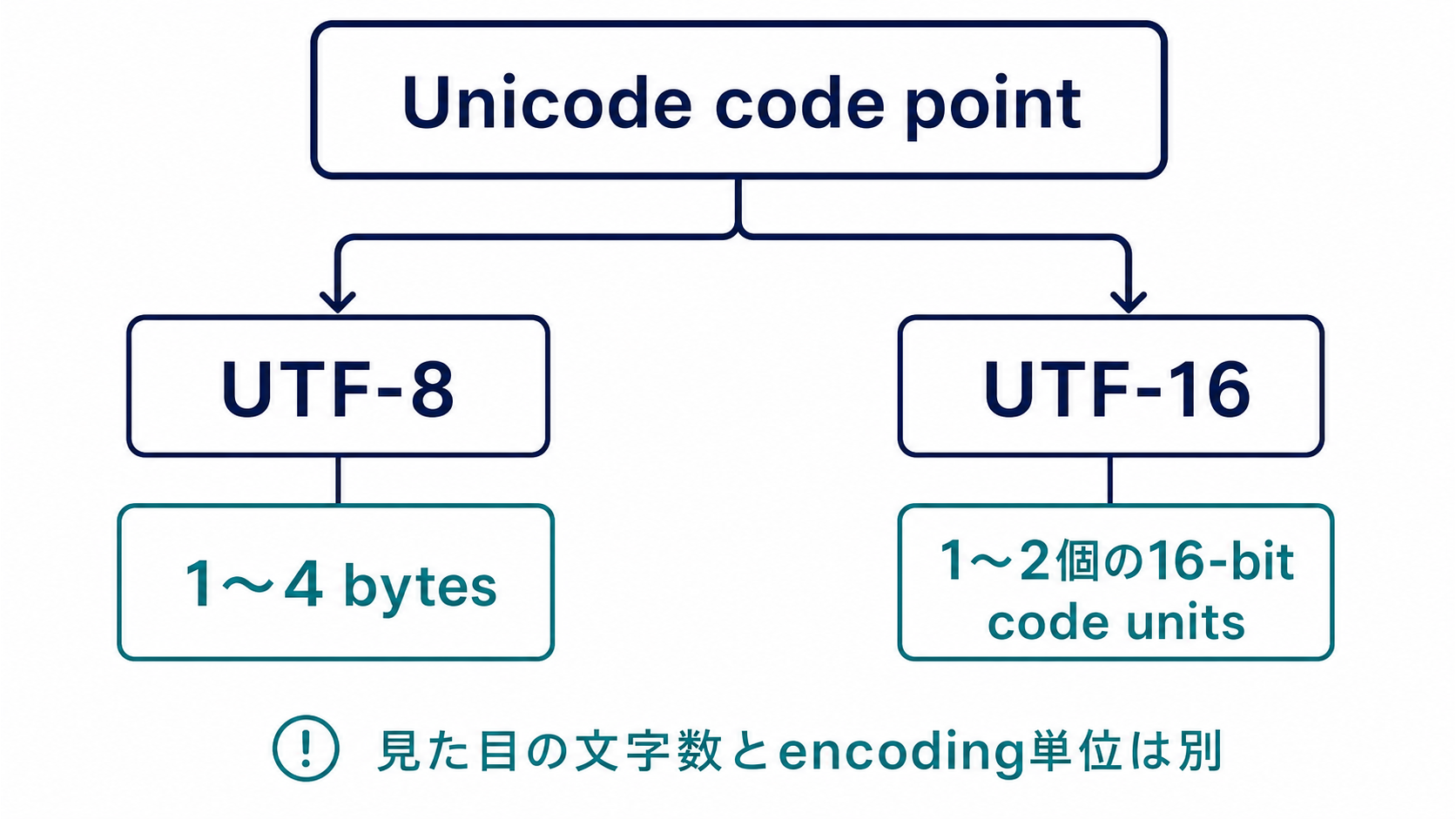
UTF-8とUTF-16は、Unicodeのコードポイントを実際のデータとして表すためのエンコーディングです。
一言でいうと
UTF-8はWebやファイル保存で広く使われ、UTF-16はJavaScript文字列の内部表現を理解する時に重要です。
比較表
| 項目 | UTF-8 | UTF-16 |
|---|---|---|
| 単位 | 8ビット単位 | 16ビット単位 |
| ASCII | 1バイト | 2バイト |
| 日本語 | 多くは3バイト | 多くは2バイト |
| 絵文字 | 多くは4バイト | 多くは4バイト、2コード単位 |
| Webでの利用 | 非常に一般的 | 内部表現で重要 |
| JavaScriptとの関係 | ファイルや通信でよく見る | 文字列処理で意識する |
UTF-8とは
UTF-8は、Unicodeの文字を1〜4バイトで表します。
英数字は1バイトで表せるため、英語中心のデータでは効率がよいです。現代のWebページ、JSON、ソースコード、API通信ではUTF-8がよく使われます。
<meta charset="UTF-8">
HTMLでは、文字化けを避けるためにUTF-8指定を明確にしておくのが基本です。
UTF-16とは
UTF-16は、Unicodeの文字を16ビット単位で表します。多くの日本語は1つの16ビット単位で表せますが、絵文字など一部の文字は2つの16ビット単位を使います。
JavaScriptの length や charCodeAt() は、このUTF-16コード単位に強く関係します。
console.log("あ".length); // 1
console.log("😀".length); // 2
サロゲートペア
UTF-16で1つのコードポイントを2つのコード単位で表す組み合わせを、サロゲートペアと呼びます。
const emoji = "😀";
console.log(emoji.length); // 2
console.log(emoji.charCodeAt(0).toString(16));
console.log(emoji.charCodeAt(1).toString(16));
見た目は1文字でも、内部では2つに分かれることがあります。
Web開発での使い分け
| 場面 | 意識するもの |
|---|---|
| HTMLファイル保存 | UTF-8 |
| JSON API | UTF-8 |
| HTTPヘッダーのcharset | UTF-8 |
JavaScriptの length | UTF-16コード単位 |
charCodeAt() | UTF-16コード単位 |
codePointAt() | Unicodeコードポイント |
ファイルや通信ではUTF-8、JavaScript内部の文字列操作ではUTF-16を意識します。
よくある誤解
| 誤解 | 実際 |
|---|---|
| UTF-8とUnicodeは同じ | UTF-8はUnicodeを表す方式の1つです |
| UTF-16なら全文字が2バイト | 一部の文字は4バイト相当になります |
| JavaScriptの文字数は見た目通り | UTF-16コード単位で数えます |
| 日本語ならUTF-16だけ考えればよい | WebやファイルではUTF-8が重要です |
まとめ
UTF-8はWebやファイル保存でよく使われるエンコーディングで、UTF-16はJavaScriptの文字列操作を理解する時に重要です。文字化けを防ぐにはUTF-8、length や charCodeAt() の挙動を読むにはUTF-16を意識します。
参考リソース
← 一覧に戻るPR
PR